
Grok 4.1 Scores 93.5 on AI Benchmark, Beats GPT-5.1
- Grok just claimed a spot near the top of one of AI’s toughest reasoning tests. The latest Grok 4.1 Fast Reasoning model scored 93.5 on the Extended NYT Connections benchmark, putting it in second place overall. That’s ahead of GPT-5.1 and within striking distance of the current leader, Gemini 3 Pro.
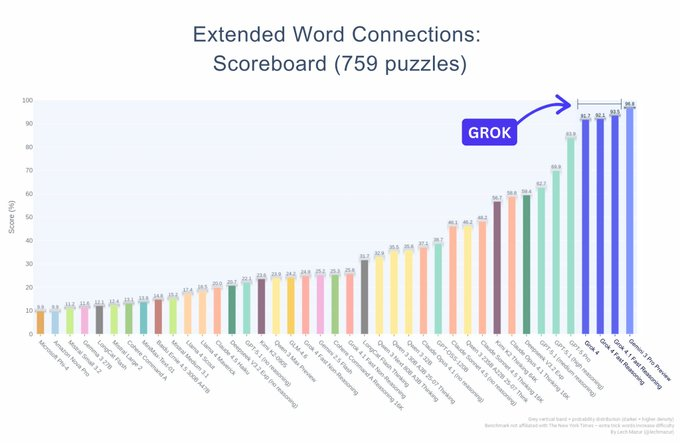
- The benchmark tested systems across 759 puzzles, and Grok didn’t just show up once. Three Grok models landed in the top tier: Grok 4.1 Fast at 93.5, Grok 4 Fast at 92.1, and Grok 4 at 91.7. That’s a tight performance band showing the whole family can handle complex word-connection challenges.
- What’s striking is how much separation there is between the leaders and everyone else. Most competing models cluster between 10% and 70% on the chart. Only a handful of frontier systems are breaking into the high 90s, which means the gap at the top is razor-thin.
The tight clustering at the top suggests that even small score differentials can influence momentum and how organizations evaluate next-generation systems.
- Beating GPT-5.1 is no small thing. It shows Grok is holding its own against OpenAI’s latest in a benchmark designed to test real reasoning ability, not just pattern matching. The Extended NYT Connections test pushes models to find abstract relationships between words, something that’s proven difficult for AI systems that rely too heavily on memorization.
- These results matter because they highlight how fast the AI race is moving. When multiple models are scoring within a few points of each other at the top, every improvement counts. Grok’s performance signals that competition in advanced reasoning isn’t slowing down—it’s tightening.
My Take: Grok’s back-to-back top finishes show xAI isn’t playing around. Scoring above GPT-5.1 on a reasoning benchmark this competitive proves the model can handle nuanced tasks. With three versions in the top tier, momentum is clearly building.
Source: X Freeze


