
NVIDIA Nemotron-Cascade 14B Model Reaches 75% Accuracy Through Sequential RL Training
- NVIDIA has published the Nemotron-Cascade training stages on Hugging Face, providing a transparent look at how a state-of-the-art reasoning AI model is constructed. The update centers on the Nemotron-Cascade 14B “Thinking” model and its structured reinforcement learning pipeline.
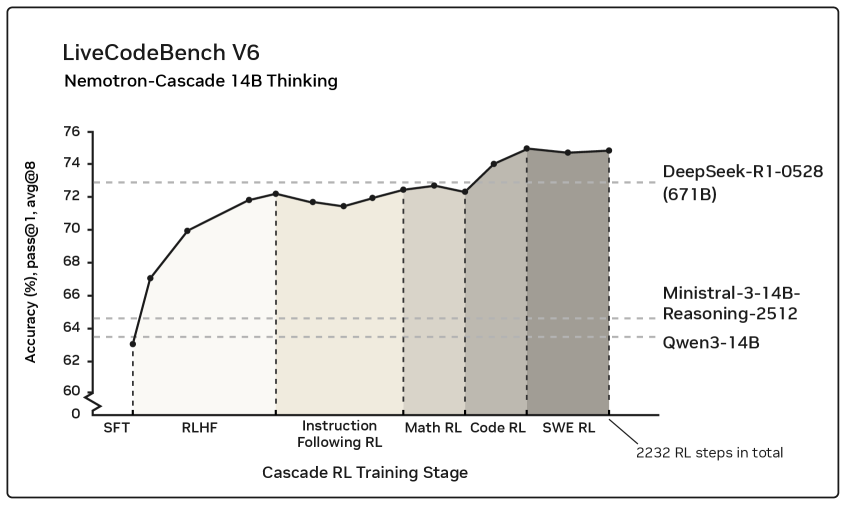
- The proposal relates to NVIDIA’s decision to build Nemotron-Cascade using cascading reinforcement learning stages rather than a single training pass. The process begins with supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF), then moves through Instruction Following RL, Math RL, Code RL, and finally Software Engineering RL. The LiveCodeBench V6 benchmark chart shows accuracy rising steadily from the low-60 percent range at the SFT stage to approximately 75–76 percent pass@1 avg@8 after SWE RL.
- The risk with such a staged reinforcement strategy is that increasing reliance on domain-specific optimization may raise complexity and compute cost, while potentially narrowing generalization if poorly calibrated.
NVIDIA just released Nemotron-Cascade training stages on Hugging Face. See how a state-of-the-art reasoning model is built step-by-step through sequential domain-wise reinforcement learning from SFT → RLHF → Math → Code → SWE.
- From a financial impact perspective, this method signals continued strategic investment by NVIDIA into advanced AI model training, which could shape expectations around the economics of reinforcement learning pipelines as they move closer to commercial deployment. An alternative approach used elsewhere is unified large-scale training without multi-stage RL specialization. That model is typically cheaper to run but may not match the structured performance improvements evident in the Nemotron-Cascade chart.
- Broader context includes the growing conversation around how reinforcement learning techniques should evolve, including how research funding, compute allocation, employment demand, and governance frameworks may adapt. As the AI industry expands, NVIDIA’s detailed documentation of Nemotron-Cascade may inform future policy debates and provide clarity on how staged training impacts capability gains.
- Expert commentary underscores NVIDIA’s intent for transparency, emphasizing the invitation to see how a state-of-the-art reasoning model is built step-by-step. The Nemotron-Cascade release reinforces NVIDIA’s role not only as a leader in hardware but also as a developer of advanced reasoning AI systems, which may carry meaningful long-term industry implications.
My Take: NVIDIA’s transparent documentation of Nemotron-Cascade’s staged training represents a significant shift toward open AI development methodology. The 15% accuracy improvement from SFT to final SWE RL stage demonstrates measurable value in domain-specific reinforcement learning, though compute costs remain a critical consideration for broader industry adoption.
Source: DailyPapers


