
GPT-5.2-Pro Shows 49.4% Pass Rate in Terminal Bench 2 Results
- Terminal Bench 2.0 results shared publicly indicate that GPT-5.2-pro performs below earlier OpenAI models. The data has prompted questions about why these outcomes were not included in official reporting.
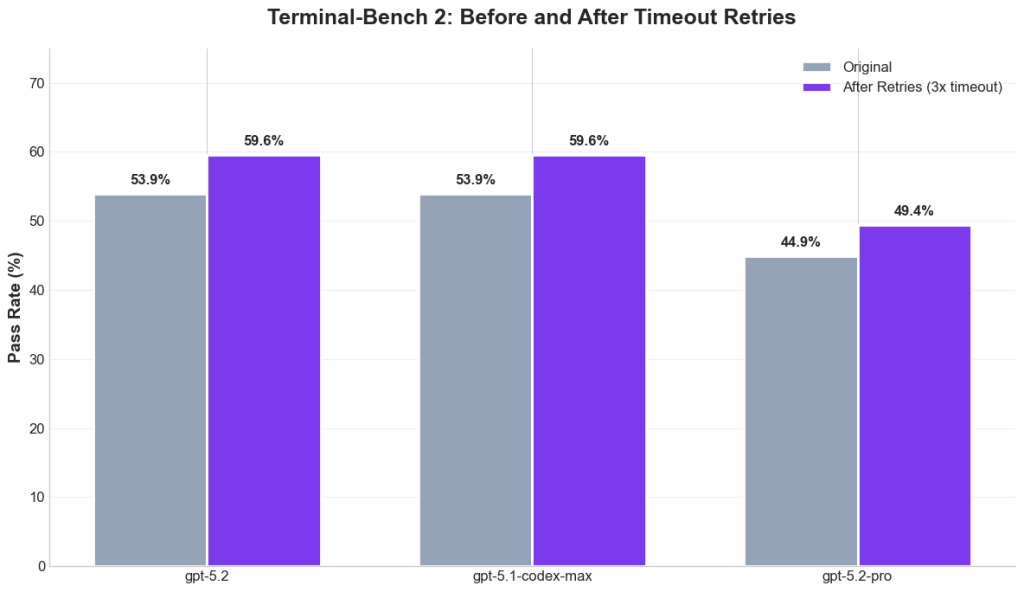
- The chart compares pass rates before and after timeout retries, showing that the newer pro variant does not achieve parity with earlier models. According to the data, GPT-5.2 and GPT-5.1-codex-max both reach a 59.6 percent pass rate after retries, while GPT-5.2-pro reaches 49.4 percent, remaining clearly lower.
- The image also shows original pass rates prior to retries, where GPT-5.2 and GPT-5.1-codex-max each record 53.9 percent, compared with 44.9 percent for GPT-5.2-pro. These results suggest that even with extended retry mechanisms, GPT-5.2-pro does not close the performance gap. The benchmark comparison focuses specifically on Terminal Bench 2 and does not include other evaluation suites or workloads beyond what is shown in the chart.
Seemed GPT-5.2-pro is doing worse than GPT-5.2 and even GPT-5.1-codex-max on Terminal Bench 2.0
- The discussion centers on transparency rather than product direction. The explicit question remains why these benchmark results were not included in a broader report, implying concern over selective disclosure rather than model capability in general.
- From a broader perspective, benchmark reporting plays a critical role in how developers, enterprises, and researchers interpret model progress. Terminal Bench results are often used to assess reliability in execution-heavy tasks, and differences of this magnitude can influence model selection for production environments. When newer variants underperform predecessors on the same benchmark, clear disclosure helps prevent misaligned expectations.
- Overall, the chart and accompanying commentary highlight a specific performance discrepancy on Terminal Bench 2. The data does not suggest conclusions beyond this benchmark, but it does reinforce the importance of comprehensive reporting as AI model families expand and diversify.
My Take: Performance gaps of this scale on standardized benchmarks deserve full disclosure. When a newer model variant trails predecessors by 10+ percentage points, transparency becomes essential for informed deployment decisions.
Source: Xiangyi Li


